
مقیاسپذیری؛ محرک اصلی پیشرفتهای AI

جهانصنعت– مسیر رسیدن به سامانههای پیشرفته اخیر هوشمصنوعی بیشتر به ساختن سیستمهای بزرگتر وابسته بوده است تا به انجام پیشرفتهای علمی.
ورونیکا سامبورسکا در مقالهای مینویسد: برای بخش اعظم تاریخ هوشمصنوعی بسیاری از پژوهشگران انتظار داشتند که ساخت سامانههای واقعا توانمند نیازمند مجموعهای طولانی از پیشرفتهای علمی باشد: الگوریتمهای انقلابی، بینشهای عمیق از شناخت انسان یا پیشرفتهای بنیادی در فهم ما از مغز. هرچند پیشرفتهای علمی نقش داشتند اما پیشرفتهای اخیر در هوشمصنوعی یک نکته غیرمنتظره را آشکار کرد: بخش زیادی از بهبودهای اخیر در تواناییهای هوشمصنوعی نتیجه مقیاسپذیرکردن سامانههای موجود بوده است. در اینجا «مقیاسپذیری» یعنی بهکارگیری توان محاسباتی بیشتر، استفاده از دادههای بزرگتر و ساخت مدلهای بزرگتر. این رویکرد تاکنون بهطور شگفتانگیزی موثر بوده است. فقط چند سال پیش سامانههای پیشرفته هوشمصنوعی در انجام وظایف سادهای مانند شمارش مشکل داشتند اما امروز این سامانهها میتوانند مسائل ریاضی پیچیده حل کرده، نرمافزار نوشته، تصاویر و ویدئوهای بسیار واقعی بسازند و درباره موضوعات دانشگاهی بحث کنند. این مقاله مروری کوتاه بر مقیاسپذیری در هوشمصنوعی طی سالهای اخیر ارائه میدهد. دادهها از سازمان Epoch است؛ سازمانی که روندهای محاسبات، داده و سرمایهگذاریها را بررسی میکند تا ببیند هوشمصنوعی به کدامسو میرود. Epoch گستردهترین پایگاه داده مربوط به مدلهای هوشمصنوعی را نگهداری کرده و مرتبا شاخصهای کلیدی درباره رشد و تغییرات این حوزه منتشر میکند.
مقیاسپذیری(Scaling) در مدلهای هوشمصنوعی چیست؟
بیایید مختصر بررسی کنیم که مقیاسپذیری در هوشمصنوعی به چه معناست. مقیاسپذیری به افزایش سه مولفه اصلی در طول آموزش مدل اشاره دارد که معمولا باید همزمان رشد کنند:
۱.حجم دادههای مورد استفاده برای آموزش هوشمصنوعی.
۲.اندازه مدل که با «پارامترها» اندازهگیری میشود.
۳.منابع محاسباتی که اغلب در هوشمصنوعی به آنها «محاسبات» یا compute گفته میشود.
ایده ساده اما قدرتمند است: سیستمهای بزرگتر هوشمصنوعی آموزشدیده با دادهها و استفاده از منابع محاسباتی بیشتر معمولا عملکرد بهتری دارند. حتی بدون تغییرات بنیادی در الگوریتمها این رویکرد اغلب باعث بهبود عملکرد در بسیاری از وظایف میشود. یک دلیل دیگر اهمیت این موضوع این است که وقتی پژوهشگران این سیستمهای هوشمصنوعی را بزرگتر میکنند نهتنها در وظایفی که روی آنها آموزش دیده عملکرد بهتری پیدا میکنند بلکه گاهی تواناییهای جدیدی نیز بهدست میآورند که در مقیاس کوچکتر نداشتند. برای مثال مدلهای زبانی در ابتدا در حل مسائل ساده حساب مانند جمع سهرقمی مشکل داشتند اما مدلهای بزرگتر پس از رسیدن به اندازهای مشخص بهراحتی میتوانستند این مسائل را حل کنند. این انتقال یک بهبود تدریجی و آرام نبوده بلکه یک جهش ناگهانی در قابلیتها بود. این جهش ناگهانی در قابلیتها بهجای بهبود تدریجی میتواند نگرانکننده باشد. اگر مثلا مدلها ناگهان رفتارهای غیرمنتظره و بالقوه مضر از خود نشان دهند صرفا بهدلیل بزرگترشدن پیشبینی و کنترل آنها سختتر خواهد بود. بههمین دلیل پیگیری و اندازهگیری این شاخصها اهمیت زیادی دارد.
۳مولفه اصلی مقیاسپذیری
۱- دادهها: افزایش حجم دادههای آموزشی
یکی از روشهای نگاه به مدلهای هوشمصنوعی امروزی این است که آنها را سیستمهای تشخیص الگو بسیار پیشرفته در نظر بگیریم. این مدلها با شناسایی و یادگیری از قاعدههای آماری موجود در متن، تصاویر یا سایر دادههایی که روی آنها آموزش دیدند عمل میکنند. هرچه مدل به دادههای بیشتری دسترسی داشته باشد میتواند جزئیات و پیچیدگیهای حوزه دانش که برای آن طراحی شده را بهتر یاد بگیرد. در سال۱۹۵۰ کلود شانون یکی از نخستین نمونههای هوشمصنوعی را ساخت: موش رباتیک تزیوس که میتوانست مسیر خود در یکهزارتو را با استفاده از مدارهای رله ساده به خاطر بسپارد. هر دیواری که تزیوس به آن برخورد میکرد به یک نقطه داده تبدیل میشد و به موش اجازه میداد مسیر صحیح را یاد بگیرد. تعداد کل دیوارها یا نقاط داده۴۰ بود. این داده را میتوان در نمودار۱ مشاهده کرد و اولین نقطه آن مربوط به تزیوس است. درحالیکه تزیوس تنها وضعیتهای دودویی ساده را در مدارهای رله ذخیره میکرد سیستمهای مدرن هوشمصنوعی از شبکههای عصبی گسترده استفاده میکنند که میتوانند الگوها و روابط بسیار پیچیدهتری را آموخته و به این ترتیب میلیاردها نقطه داده را پردازش کنند. تمام مدلهای برجسته اخیر بهویژه مدلهای بزرگ و پیشرفته بر مقدار عظیمی از دادههای آموزشی متکی هستند. باتوجهبه محور عمودی که در مقیاس لگاریتمی نمایش داده شده نمودار۱ نشان میدهد که دادههای مورد استفاده برای آموزش مدلهای هوشمصنوعی بهشکل نمایی رشد کردند. از ۴۰نقطه داده برای تزیوس تا تریلیونهانقطه داده برای بزرگترین سیستمهای مدرن در مدت کمی بیش از هفتدهه. از سال۲۰۱۰ حجم دادههای آموزشی تقریبا هر ۹تا۱۰ماه دوبرابر شده است. این رشد سریع را میتوان در نمودار مشاهده کرد که با خط بنفش از ابتدای۲۰۱۰ تا اکتبر۲۰۲۴ (آخرین نقطه داده هنگام نگارش مقاله) نشان داده شده است. مجموعه دادههای مورد استفاده برای آموزش مدلهای بزرگ زبان بهویژه رشد سریعتری داشته و از سال۲۰۱۰ هر سال تقریبا سهبرابر شدند. مدلهای بزرگ زبان متن را با شکستن به توکنها واحدهای پایهای که مدل میتواند رمزگذاری و درک کند، پردازش میکنند. یک توکن مستقیما معادل یک کلمه نیست اما بهطور متوسط سهکلمه انگلیسی تقریبا معادل چهارتوکن است. مدلGPT-2 که در سال۲۰۱۹ عرضه شد براساس برآوردها روی ۴میلیارد توکن آموزش دیده که تقریبا معادل ۳میلیارد کلمه است. برای مقایسه در سپتامبر۲۰۲۴ ویکیپدیای انگلیسی حدود ۶/۴میلیارد کلمه داشت. در مقایسه GPT-4 که در سال۲۰۲۳ منتشر شد تقریبا روی ۱۳تریلیونتوکن یا حدود ۷۵/۹تریلیون کلمه آموزش دیده است. این بدان معناست که حجم دادههای آموزشی GPT-4 بیش از ۲هزاربرابر متن کل ویکیپدیای انگلیسی بوده است. با استفاده از دادههای بیشتر برای آموزش مدلهای هوشمصنوعی ممکن است درنهایت با کمبود مواد با کیفیت تولیدشده توسط انسان مانند کتابها، مقالات و پژوهشها مواجه شویم. برخی پژوهشگران پیشبینی میکنند که ممکن است طی چند دهه آینده منابع آموزشی مفید به پایان برسند. درحالی که خود مدلهای هوشمصنوعی میتوانند دادههای زیادی تولید کنند آموزش مدلها با مواد تولیدشده توسط ماشین میتواند مشکلاتی ایجاد کرده و باعث کمدقتتر و تکراریترشدن مدلها شوند.
۲- پارامترها: افزایش اندازه مدل
افزایش حجم دادههای آموزشی به مدلهای هوشمصنوعی اجازه میدهد تا از اطلاعات بسیار بیشتری نسبت به گذشته بیاموزند. با این حال برای شناسایی الگوها در این دادهها و یادگیری موثر مدلها به چیزی به نام پارامترها نیاز دارند. پارامترها مانند پیچهایی هستند که میتوان آنها را تنظیم کرد تا نحوه پردازش اطلاعات و پیشبینیهای مدل بهبود یابد. هرچه حجم دادههای آموزشی بیشتر شود مدلها به ظرفیت بیشتری برای درک تمام جزئیات دادهها نیاز دارند. این به این معنی است که مجموعه دادههای بزرگتر معمولا نیازمند مدلهایی با پارامترهای بیشتر برای یادگیری موثر هستند. شبکههای عصبی اولیه دارای صدها یا هزارانپارامتر بودند. مدل تزیوس با مدار ساده یادگیری مسیر درهزارتو تنها ۴۰پارامتر داشت یعنی معادل تعداد دیوارهایی که با آنها برخورد میکرد. مدلهای بزرگ اخیر مانند GPT-3 تا ۱۷۵میلیاردپارامتر دارند. اگرچه این عدد بزرگ به نظر میرسد ذخیره آن روی دیسک حدود ۷۰۰گیگابایت فضا میگیرد که به راحتی توسط کامپیوترهای امروزی مدیریت میشود. نمودار۲ نشان میدهد که تعداد پارامترها در مدلهای هوشمصنوعی در طول زمان بهشدت افزایش یافته است. از سال۲۰۱۰ تعداد پارامترهای مدلهای هوشمصنوعی تقریبا هرسال دوبرابر شده است. بالاترین تعداد پارامتر ثبتشده توسط Epoch در مدل QMoE برابر با ۶/۱تریلیون بوده است. درحالی که مدلهای بزرگتر میتوانند کارهای بیشتری انجام دهند با مشکلاتی نیز مواجه هستند. یکی از مهمترین مسائل «بیشبرازش» است. این اتفاق زمانی رخ میدهد که مدل هوشمصنوعی بیش از حد برای پردازش دادههای خاصی که روی آن آموزش دیده بهینه شود اما در مواجهه با دادههای جدید عملکرد ضعیفی داشته باشد. برای مقابله با این مشکل پژوهشگران از دو راهکار استفاده میکنند:
– پیادهسازی تکنیکهای تخصصی برای یادگیری عمومیتر.
– افزایش حجم و تنوع دادههای آموزشی.
۳- توان محاسباتی: افزایش منابع محاسباتی
با افزایش دادهها و پارامترهای مدلهای هوشمصنوعی آنها به منابع محاسباتی بهطور نمایی بیشتری نیاز پیدا میکنند. این منابع که در تحقیقات هوشمصنوعی معمولا با اصطلاح محاسبات شناخته شدند معمولا با تعداد کل عملیات نقطهمعمولی شناور (FLOP) سنجیده میشوند که هر FLOP نمایانگر یک محاسبه عددی ساده مانند جمع یا ضرب است. نیازهای محاسباتی برای آموزش هوشمصنوعی درطول زمان بهطور چشمگیری تغییر کرده است. مدلهای اولیه با دادهها و پارامترهای محدود میتوانستند در عرض چندساعت روی سختافزار ساده آموزش ببینند اما مدلهای پیشرفته امروز نیازمند صدها روز محاسبات مداوم حتی با دههاهزار کامپیوتر ویژه هستند. نمودار۳ نشان میدهد که توان محاسباتی مورداستفاده برای آموزش هر مدل هوشمصنوعی که در محور عمودی نمایش داده شده در دهههای اخیر بهطور پیوسته و نمایی افزایش یافته است. از سال۱۹۵۰تا۲۰۱۰ توان محاسباتی تقریبا هر دوسال دوبرابر شد. با این حال از سال۲۰۱۰ این رشد بهطور چشمگیری شتاب گرفته و اکنون تقریبا هر ششماه دوبرابر میشود بهطوری که مدل پرمصرفترین توان محاسباتی به میزان ۵۰میلیارد پتاFLOP رسیده است. برای درک این مقیاس یککارت گرافیک پیشرفته مانند NVIDIA GeForce RTX 3090 که بهطور گسترده در تحقیقات هوشمصنوعی استفاده میشود اگر تمام ظرفیت خود را برای یک سال کامل بهکار گیرد تنها میتواند ۱/۱میلیون پتاFLOP محاسبه انجام دهد. ۵۰میلیارد پتاFLOP تقریبا ۴۵۴۵۵ برابر بیشتر از این مقدار است. دستیابی به محاسبات در این مقیاس نیازمند سرمایهگذاریهای بزرگ در انرژی و سختافزار است. هزینه آموزش برخی از مدلهای پیشرفته تا ۴۰میلیوندلار برآورد شده بنابراین فقط در دسترس تعداد معدودی از سازمانهای با بودجه کافی قرار دارد.
همزمانی مقیاسپذیری توان محاسباتی، دادهها و پارامترها
توان محاسباتی، دادهها و پارامترها هنگام مقیاسپذیری مدلهای هوشمصنوعی بهطور نزدیکی با یکدیگر مرتبط هستند. وقتی مدلهای هوشمصنوعی با دادههای بیشتری آموزش داده میشوند موضوعات بیشتری برای یادگیری وجود دارد. برای اینکه مدل بتواند پیچیدگی فزاینده دادهها را مدیریت کند نیاز به پارامترهای بیشتری دارد تا از ویژگیهای مختلف دادهها یاد بگیرد. افزودن پارامترهای بیشتر به مدل نیز به معنای نیاز به منابع محاسباتی بیشتر در حین آموزش است. این وابستگی متقابل بدین معناست که دادهها، پارامترها و توان محاسباتی باید بهطور همزمان رشد کنند. بزرگترین مجموعههای داده عمومی امروز حدود ۱۰برابر بزرگتر از آن چیزی هستند که اکثر مدلهای هوشمصنوعی فعلی استفاده میکنند و برخی از آنها شامل صدها تریلیون کلمه هستند اما بدون توان محاسباتی و پارامترهای کافی مدلهای هوشمصنوعی هنوز نمیتوانند از این دادهها برای آموزش استفاده کنند.
چه چیزی میتوانیم از این روندها برای آینده هوشمصنوعی بیاموزیم؟
شرکتها درپی جذب سرمایهگذاریهای کلان برای توسعه و مقیاسبندی مدلهای هوشمصنوعی خود هستند و تمرکز روزافزونی بر فناوریهای هوشمصنوعی مولد دارند. درهمینحال سختافزارهای کلیدی مورد استفاده در آموزش یعنی کارتهای گرافیک (GPU) ارزانتر و قدرتمندتر شدند بهطوری که سرعت محاسباتی آنها تقریبا هر ۵/۲سال برای هردلار هزینه دوبرابر میشود. برخی سازمانها اکنون از منابع محاسباتی بیشتر نهتنها درمرحله آموزش مدلها بلکه در مرحله استنتاج و مرحلهای که مدلها پاسخ تولید کرده استفاده میکنند، همانطور که مدل جدید o1 شرکت OpenAI نشان میدهد. این تحولات میتوانند به ایجاد فناوریهای پیشرفتهتر هوشمصنوعی سریعتر و ارزانتر کمک کنند. با سرمایهگذاری بیشتر شرکتها و بهبود سختافزارهای مورد نیاز ممکن است شاهد پیشرفتهای قابلتوجهی در قابلیتهای هوشمصنوعی ازجمله تواناییهای جدید و شاید غیرمنتظره باشیم زیرا این تغییرات میتوانند تاثیرات بزرگی بر جامعه ما داشته باشند و مهم است که از همان ابتدا این تحولات را رصد و درک کنیم.
نمودار ۱.رشد نمایی تعداد نقاط داده استفادهشده برای آموزش سیستمهای مهم هوشمصنوعی
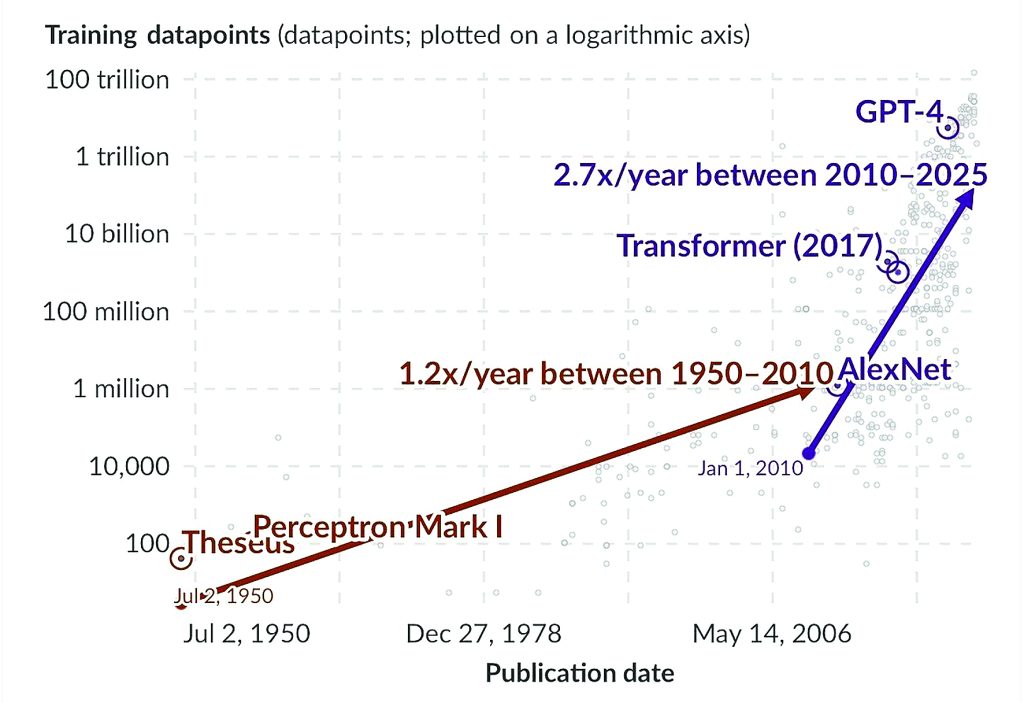
یادداشت: هر حوزه هوشمصنوعی یک واحد مشخص برای اندازهگیری «نقاط داده» دارد. برای مثال: در پردازش تصویر واحد اندازهگیری تصاویر، در پردازش زبان واحد واژهها (یا توکنها) و در بازیها واحد گامهای زمانی (timesteps) است. به همین دلیل سیستمها فقط درصورتی قابل مقایسه مستقیم هستند که در یک حوزه مشابه قرار داشته باشند.
Data source: Epoch AI (2025)
نمودار ۲.رشد نمایی تعداد پارامترها در سیستمهای مهم هوشمصنوعی
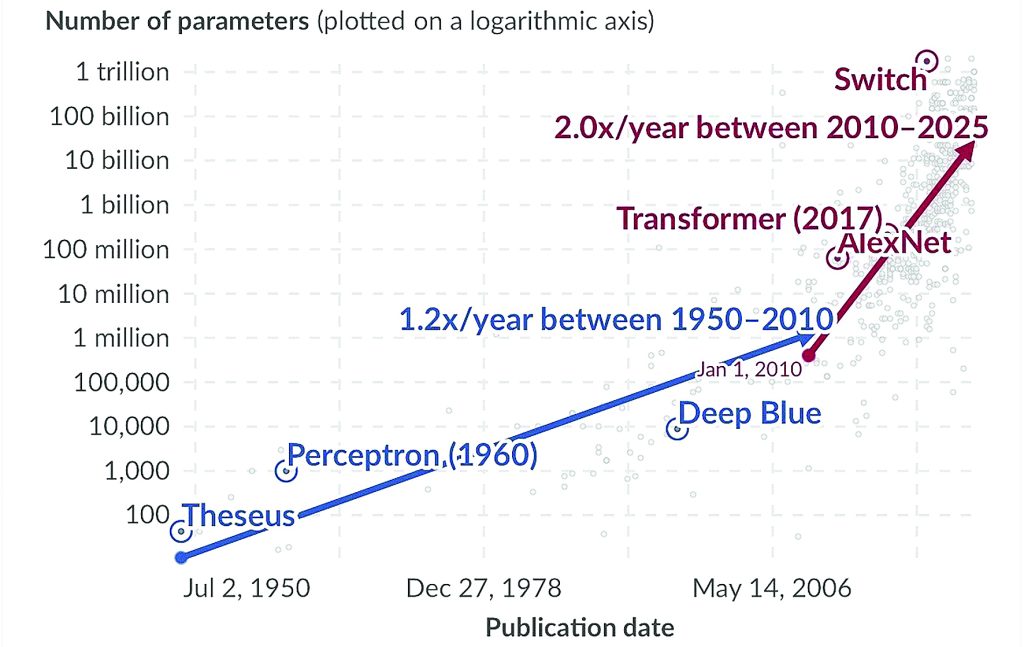
یادداشت: پارامترها متغیرهایی در یک سیستم هوشمصنوعی هستند که مقادیر آنها در طی فرآیند آموزش تنظیم شده تا تعیین کنند داده ورودی چگونه به خروجی موردنظر تبدیل شود، مانند وزنهای اتصالات در یک شبکه عصبی مصنوعی.
Data source: Epoch AI (2025)
نمودار ۳. رشد نمایی مقدار محاسبات در آموزش سیستمهای مهم هوشمصنوعی
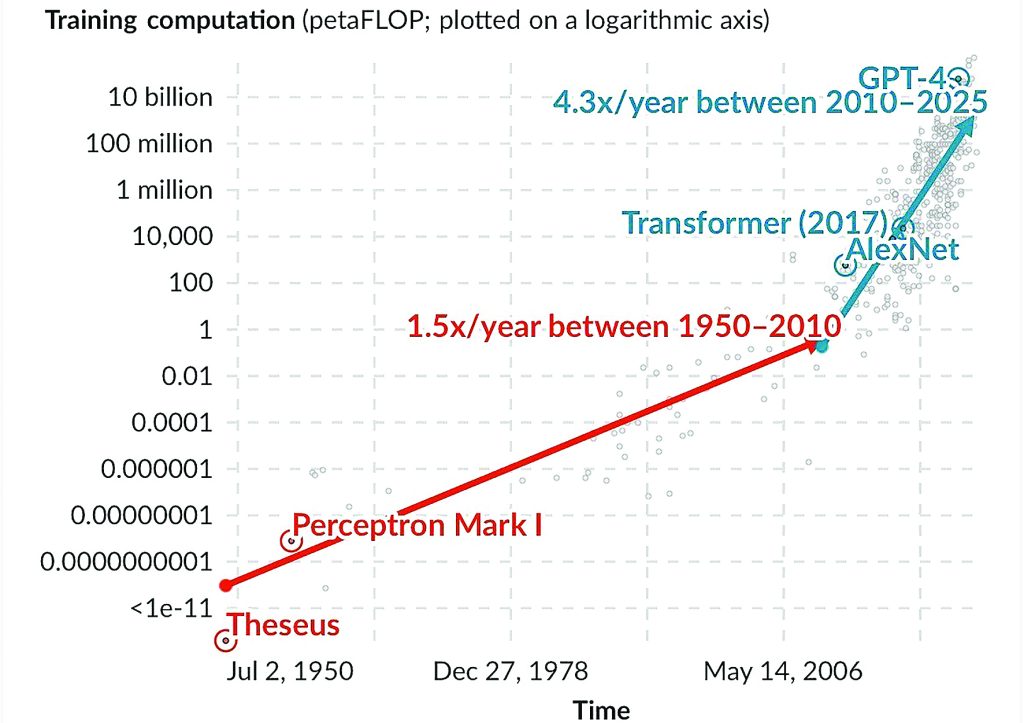
یادداشت: مقدار محاسبات (Compute) براساس مجموع پتافلاپ اندازهگیری میشود و هر پتافلاپ برابر است با ۱۰^۱۵عملیات ممیز شناور.
Data source: Epoch AI (2025)
