الگوریتم ،هوش مصنوعی و رادیولوژی

جهانصنعت– رادیولوژی ترکیبی است از تصاویر دیجیتال، شاخصهای روشن و وظایف قابل تکرار اما جایگزین کردن انسان با هوش مصنوعی سختتر از آن چیزی است که به نظر میرسد.
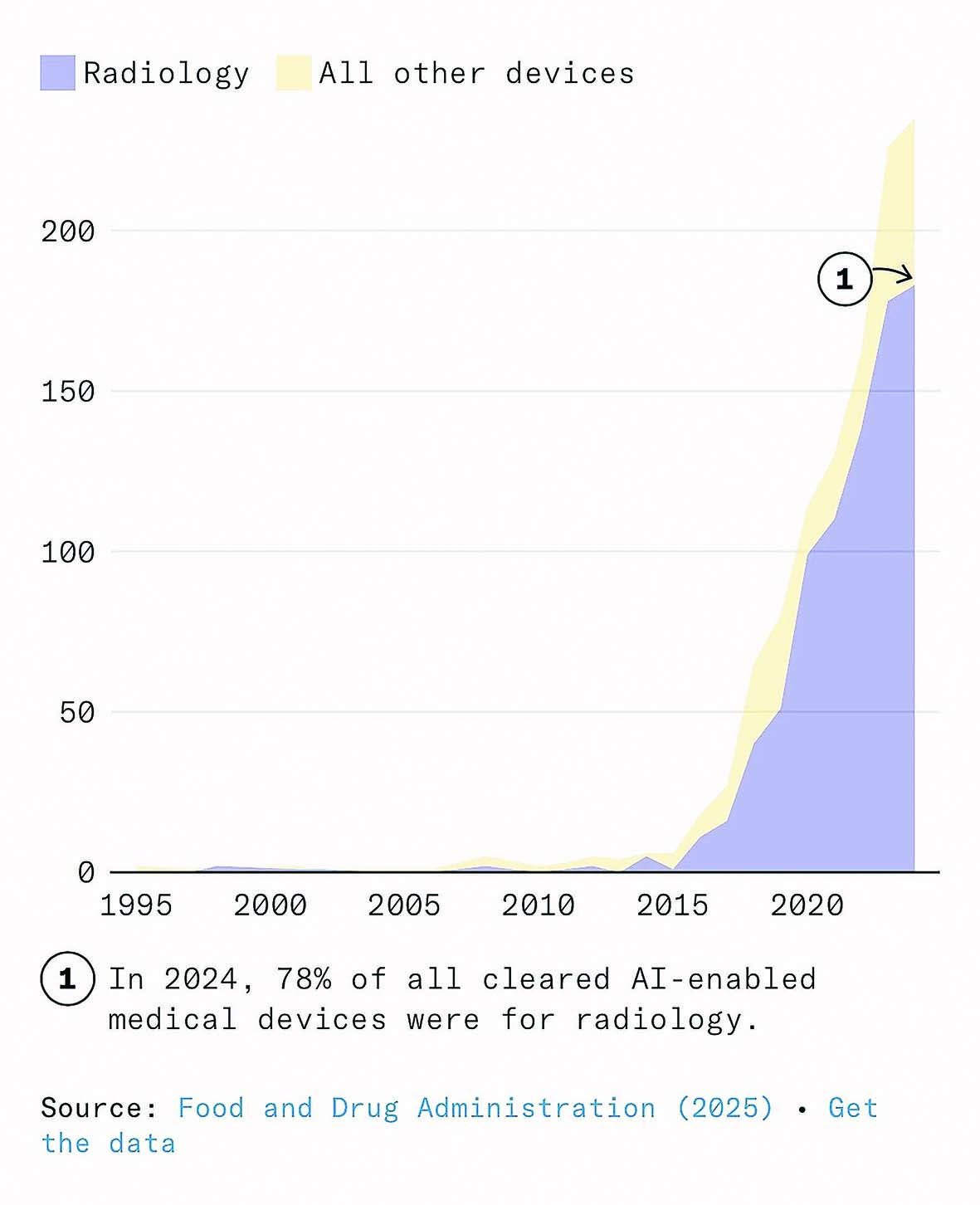
CheXNet میتواند ذاتالریه را با دقتی بیشتر از یک گروه رادیولوژیستهای دارای بورد تخصصی تشخیص دهد. این یک مدل هوش مصنوعی است که در سال ۲۰۱۷ منتشر شد و با بیش از ۱۰۰هزار تصویر اشعه ایکس قفسه سینه آموزش دیده است. این مدل سریع، رایگان و قابل اجرا روی یک کارت گرافیک معمولی خانگی است. یک بیمارستان میتواند از آن استفاده کند تا یک اسکن جدید را در کمتر از یکثانیه طبقهبندی کند. از آن زمان تاکنون شرکتهایی مانند Annalise.ai، Lunit، Aidoc، و Qure.ai مدلهایی ارائه کردهاند که میتوانند صدها بیماری را در انواع مختلف اسکن و با دقت و سرعتی بیش از رادیولوژیستهای انسانی در آزمونهای معیار، شناسایی کنند. برخی از محصولات میتوانند فهرست کاری رادیولوژیستها را دوباره مرتب کنند تا موارد بحرانی در اولویت قرار گیرند و مراحل بعدی را به تیم مراقبت پیشنهاد دهند، یا گزارشهای اولیه ساختاریافتهای تولید کنند که با سیستمهای ثبت بیمارستانی سازگار است. چند مورد مانند LumineticsCore، حتی مجوز دارند که بدون نیاز به بررسی عکس توسط پزشک کار کنند. در مجموع بیش از ۷۰۰مدل رادیولوژی دارای تاییدیه FDA وجود دارد که بیش از سهچهارم کل دستگاههای پزشکی مبتنی بر هوش مصنوعی را تشکیل میدهند.
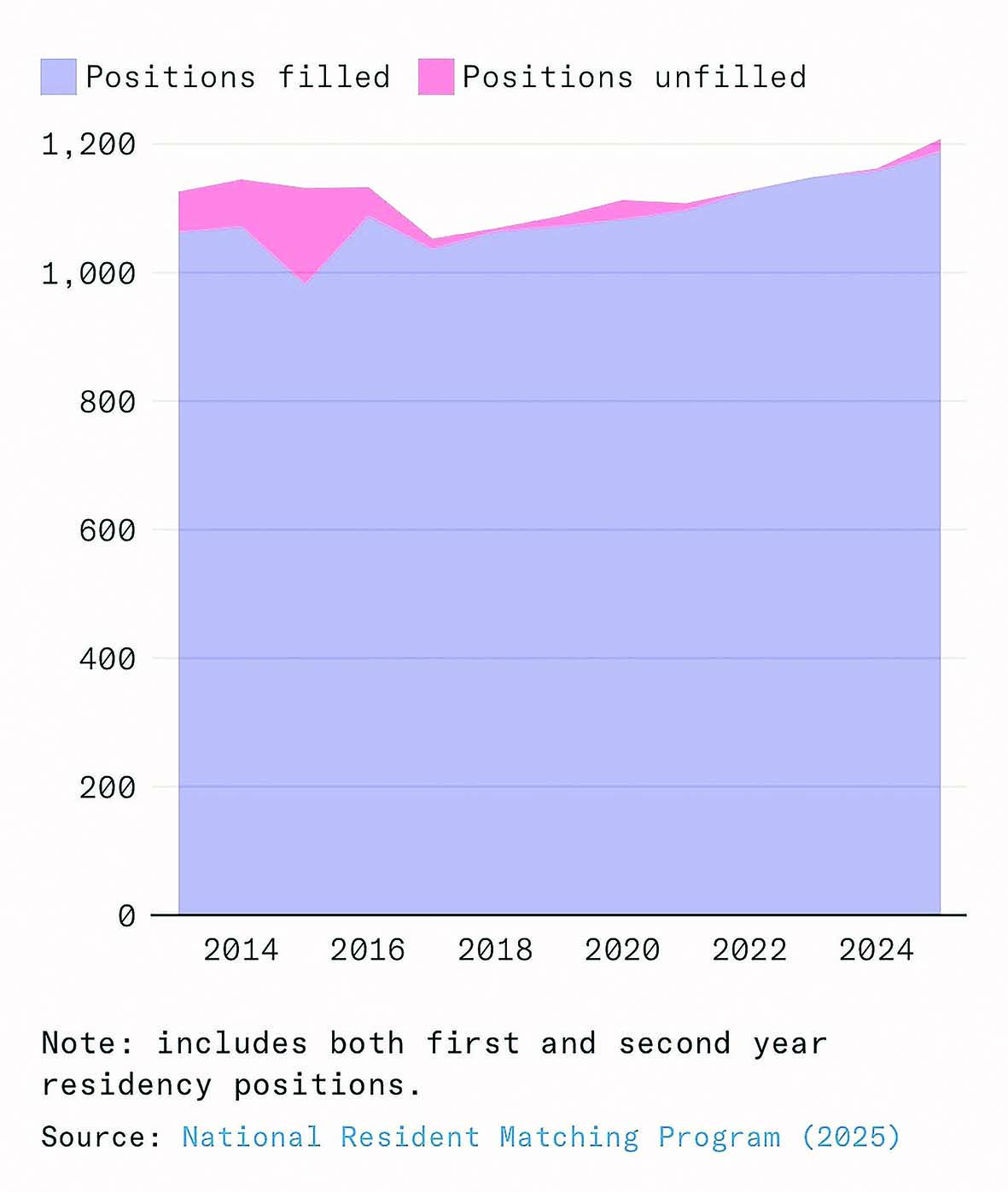
رادیولوژی حوزهای است که برای جایگزینی نیروی انسانی بهینهسازی شده است؛ جایی که ورودیهای دیجیتال، وظایف مبتنی بر تشخیص الگو و شاخصهای روشن غالب هستند. در سال ۲۰۱۶، جفری هینتون، دانشمند رایانه و برنده جایزه تورینگ اعلام کرد که «از همین حالا باید آموزش رادیولوژیستها را متوقف کرد.» اگر افراطیترین پیشبینیها درباره اثر هوش مصنوعی بر اشتغال و دستمزدها درست بود، آنگاه رادیولوژی باید مانند قناری در معدن زغالسنگ عمل میکرد و اولین نشانههای خطر را نشان میداد اما تقاضا برای نیروی انسانی بیش از هر زمان دیگری است. در سال ۲۰۲۵، برنامههای رزیدنتی رادیولوژی تشخیصی آمریکا رکورد ۱۲۰۸ موقعیت رزیدنتی را در تمام تخصصهای رادیولوژی ارائه دادند؛ افزایشی ۴درصدی نسبت به سال ۲۰۲۴. نرخ خالی بودن جایگاهها در این حوزه نیز به بالاترین سطح تاریخ خود رسیده است. در سال ۲۰۲۵، رادیولوژی دومین تخصص پردرآمد پزشکی در ایالات متحده بود، با درآمد متوسط ۵۲۰هزار دلار، یعنی بیش از ۴۸درصد بالاتر از میانگین سال ۲۰۱۵.
سه نکته این موضوع را توضیح میدهد. نخست، هرچند مدلهای هوش مصنوعی در آزمونهای استاندارد عملکردی بهتر از انسان دارند اما در محیطهای واقعی بیمارستانی نمیتوانند همان سطح عملکرد را تکرار کنند. بیشتر ابزارها فقط میتوانند ناهنجاریهایی را تشخیص دهند که در دادههای آموزشی آنها رایج بوده است و مدلها معمولا خارج از شرایط آزمون خود عملکرد ضعیفتری دارند.
دوم، تلاش برای سپردن وظایف بیشتر به مدلها با موانع قانونی مواجه شده است: فعلا نهادهای تنظیمگر و بیمههای درمانی برای تایید یا تحتپوشش قرار دادن مدلهای کاملا خودکار در رادیولوژی تردید دارند.
سوم، حتی زمانی که مدلها تشخیص دقیقی میدهند، فقط بخش کوچکی از وظایف یک رادیولوژیست را انجام میدهند. رادیولوژیستها تنها بخشی از زمان خود را صرف تشخیص میکنند و بخش عمده کارشان شامل گفتوگو با بیماران و دیگر پزشکان است.
هوش مصنوعی با سرعت در سراسر اقتصاد و جامعه در حال گسترش است اما رادیولوژی به ما نشان میدهد که این فناوری در سالهای نخست انتشار خود لزوما بر همه حوزهها مسلط نمیشود دستکم تا زمانی که این موانع برطرف شوند. بهرهگیری کامل از مزایای آن مستلزم سازگار کردن هوش مصنوعی با جامعه و سازگار کردن قواعد جامعه با هوشمصنوعی است.
جزایر اتوماسیون
همه سیستمهای هوش مصنوعی الگوریتمهایی هستند که ورودی میگیرند و خروجی میدهند. مدلهای رادیولوژی برای تشخیص یک «یافته» آموزش داده میشوند یعنی بخشی قابل اندازهگیری از شواهد که به تشخیص یا رد یک بیماری کمک میکند. بیشتر مدلهای رادیولوژی تنها یک یافته یا بیماری را در یک نوع تصویر شناسایی میکنند. برای مثال ممکن است مدلی به اسکن CT قفسه سینه نگاه کند و پاسخ دهد که آیا گرههای ریوی وجود دارد، شکستگی دندهای دیده میشود، یا امتیاز کلسیفیکاسیون شریان کرونری چقدر است. برای هر سوال جداگانه، یک مدل جدید لازم است. بنابراین برای پوشش حتی بخش کوچکی از آنچه رادیولوژیستها در یک روز میبینند باید میان دهها مدل جابهجا شوند و هر بار سوال درست را از مدل درست بپرسند. برخی پلتفرمها خروجی دهها یا حتی صدها مدل هوش مصنوعی متفاوت را مدیریت و تفسیر میکنند اما هر مدل هنوز مستقل عمل میکند و فقط یک یافته یا بیماری را تحلیل میکند. نتیجه، فهرستی از پاسخهای جداگانه به پرسشهای جداگانه است، نه یک تفسیر واحد از تصویر.
باوجود صدها الگوریتم تصویربرداری تایید شده توسط سازمان غذا و داروی آمریکا، مجموعه فعلی مدلهای رادیولوژی تنها بخش کوچکی از وظایف واقعی تصویربرداری پزشکی را پوشش میدهد. بسیاری از آنها حول چند مورد کاربردی متمرکز هستند: سکته، سرطان پستان و سرطان ریه مجموعا حدود ۶۰درصد مدلها را تشکیل میدهند اما تنها بخش اندکی از حجم واقعی تصویربرداری را در آمریکا شامل میشوند. سایر زیرشاخهها مانند تصویربرداری عروقی، سر و گردن، ستون فقرات و تیروئید در حال حاضر محصولات هوش مصنوعی اندکی دارند. بخشی از این محدودیت بهخاطر کمبود داده است: اسکن باید به اندازه کافی رایج باشد تا نمونههای متعدد و برچسبخورده برای آموزش مدل وجود داشته باشد. برخی اسکنها هم ذاتا پیچیدهترند، مانند سونوگرافی که از زوایای مختلف گرفته میشود و صفحه تصویربرداری استاندارد مانند X-ray ندارد.
وقتی مدلها در بیمارستانی متفاوت از محل آموزششان مستقر میشوند، ممکن است دچار مشکل شوند. در یک کارآزمایی استاندارد، نمونهها از چندین بیمارستان گرفته میشود تا مدل با طیف وسیعی از بیماران روبهرو باشد و اثرات خاص هر بیمارستان (مثلا روش یک پزشک یا نحوه تنظیم تجهیزات) حذف شود اما در آمریکا هنگام اخذ مجوز، معمولا مدلها روی دادههایی محدود آزمایش میشوند. در سال ۲۰۲۴، ۳۸درصد مدلهایی که محل آزمایش خود را گزارش کرده بودند، فقط روی داده یک بیمارستان تست شده بودند.
مجموعه دادههای عمومی هم اغلب فقط از یک مرکز جمعآوری میشوند.عملکرد ابزار ممکن است هنگام آزمایش خارج از نمونه (در بیمارستانهای دیگر) تا ۲۰واحددرصد کاهش یابد. در مطالعهای، مدلی که برای تشخیص ذاتالریه روی X-rayهای یک بیمارستان آموزش دیده بود، در بیمارستان دیگر بسیار ضعیفتر عمل کرد. بخشی از این مشکلات ناشی از خطاهای قابل اجتنابی مثل بیشبرازش بود اما بخشی نیز ناشی از اختلافات بنیادی در شیوه ثبت و تولید دادهها در بیمارستانهای مختلف بود، مثلا تفاوت در تجهیزات تصویربرداری. این یعنی بیمارستانها باید این مدلها را دوباره آموزش دهند یا دوباره ارزیابی کنند، حتی اگر مدل جاهای دیگر موفق عمل کرده باشد.
محدودیت مدلهای رادیولوژی ریشه در مشکلات عمیقتری در ساخت هوش مصنوعی پزشکی دارد. مجموعه دادههای آموزشی معمولا معیارهای سختی دارند: تشخیص باید کاملا روشن باشد (مثلا با تایید دو یا سه متخصص یا نتیجه پاتولوژی) و تصاویر نامعمول، تاریک یا زاویهدار حذف میشوند. این کار باعث میشود مدلها در تشخیص سادهترین موارد که پزشکان هم در آنها خوب هستند بهتر شوند اما در شرایط واقعی عملکرد ضعیف داشته باشند. در سال ۲۰۲۲ در یک مطالعه الگوریتمی که قرار بود ذاتالریه را تشخیص دهد، در تشخیص انواع خفیف، ظریف، یا موارد مشابه با بیماریهای دیگر مثل تجمع مایع در ریه یا ریهخوابرفته شکست خورد. انسانها همچنین از «زمینه اطلاعاتی» بهره میبرند: یک رادیولوژیست به من گفت مدلی که استفاده میکنند، گاهی منگنههای جراحی را خونریزی تشخیص میدهد!
مجموعه دادههای تصویربرداری پزشکی معمولا شامل موارد کمتر از کودکان، زنان و اقلیتهای قومی است، بنابراین مدلها برای این گروهها عملکرد ضعیفتری دارند. بسیاری از این دادهها جنسیت یا نژاد بیماران را اصلا ثبت نمیکنند و رفع مشکل سوگیری را دشوار میسازند. نتیجه این است که مدلهای رادیولوژی تنها بخش محدودی از واقعیت را پیشبینی میکنند. هرچند مدلها در برخی سناریوها عملکرد خوبی دارند، از جمله تشخیص بیماریهای رایجی مانند ذاتالریه یا برخی تومورها اما مشکلات به اینجا ختم نمیشود. حتی یک مدل مناسب و آموزش دیده در همان بیمارستان ممکن است در عمل به خوبیِ آزمونهای معیار عمل نکند. در مطالعات معیار، پژوهشگران مجموعهای از اسکنها را جدا میکنند، اهداف کمی مثل حساسیت و ویژگی تعریف میکنند و عملکرد مدل را با یک متخصص مقایسه میکنند اما مطالعات بالینی نشان میدهند که عملکرد مدل در محیط واقعی بسیار متفاوتتر است. از نخستین روزهای «تشخیص کامپیوتری»، فاصله قابلتوجهی میان عملکرد آزمایشگاهی و بالینی وجود داشته است.
در دهه ۱۹۹۰، سیستمهای ابتدایی
هوش مصنوعی برای کمک به تشخیص ماموگرافی ایجاد شد. در آزمایشها، ترکیب انسان و این سیستمها بهتر از انسان تنها بود. سازمان غذا و داوری آمریکا در ۱۹۹۸ آن را تایید کرد و مدیکر در ۲۰۰۱ هزینه اضافی برای استفاده از آن پرداخت. تا ۲۰۱۰ حدود ۷۴درصد ماموگرافیها با کمک این سیستمها انجام میشد اما این سیستمها ناامیدکننده بودند. بین سالهای ۱۹۹۸ تا ۲۰۰۲، مطالعهای روی ۴۳۰هزار ماموگرافی نشان داد که ابزارهای تشخیصی کامپیوتری باعث افزایش ۲۰درصدی نمونهبرداریها شد اما هیچ افزایش واقعی در کشف سرطان ایجاد نکرد. مطالعات دیگر نیز نتایج مشابهی داشتند. مقایسه دیگری میان کمک کامپیوتری و «خوانش دوگانه» یعنی بررسی هر تصویر توسط دو پزشک نشان داد که کمک کامپیوتری نرخ تشخیص سرطان را افزایش نمیدهد اما ۱۰درصد فراخوانی بیماران را بیشتر میکند. در حالی که خوانش دوگانه سرطان بیشتری را با بازگشت کمتر تشخیص میداد. بنابراین این کمکها از مراقبت معمول بدتر بودند. در ۲۰۱۸ مدیکر پرداخت اضافی برای استفاده از این ابزارها را متوقف کرد. یکی از دلایل این شکاف این است که پزشکان در محیط واقعی رفتاری متفاوت از محیط کنترلشده دارند. بهویژه، پزشکان در محیط بالینی بیش از حد به ابزارهای هوش مصنوعی تکیه میکنند. حتی در ابزارهای بسیار ابتدایی، این مشکل مشاهده شد. در مطالعهای در ۲۰۰۴، پزشکانی که از نرمافزار کمکتشخیصی استفاده کردند، تنها نیمی از سرطانها را تشخیص دادند، در حالی که گروه بدون نرمافزار ۶۸درصد موارد را یافتند. در مطالعهای دیگر در ۲۰۱۱، زمانی که سیستم، راهنمایی اشتباه میداد، خطای پزشکان ۲۶درصد بیشتر از پزشکان بدون ابزار بود.
انسان در حلقه
به نظر میرسد مدلهای بهتر و اتوماسیون بیشتر بتوانند مشکلات هوش مصنوعی فعلی در رادیولوژی را حل کنند. اگر پزشک دخیل نباشد و رفتار او عملکرد سیستم را تغییر ندهد شاید نتایج واقعی با نمرات معیار (benchmark) همخوانی پیدا کنند اما الزامات نظارتی و سیاستهای بیمهای روند استفاده از مدلهای کاملا خودکار را کند کردهاند.
سازمان غذاوداروی آمریکا، نرمافزارهای تصویربرداری را در دو دسته تنظیم میکند: ابزارهای کمکی یا «تریاژ» که لازم است یک پزشک مجاز، اسکن را بخواند و گزارش را امضا کند و ابزارهای خودکار که چنین الزامی ندارند. سازندگان ابزارهای کمکی فقط باید نشان دهند که عملکرد آنها با ابزارهای مشابه موجود هماهنگ است اما ابزارهای خودکار باید استاندارد بسیار سختتری را برآورده کنند: مدل باید ثابت کند که اگر تصویر تار باشد و از اسکنر غیرمعمولی استفاده شده باشد یا مورد خارج از حوزه تخصص مدل باشد، از خواندن آن خودداری میکند. دلیل سختگیری این است که پس از حذف انسان از فرآیند، یک خطای پنهان نرمافزاری میتواند قبل از آشکار شدن به هزاران بیمار آسیب بزند. رسیدن به این استاندارد دشوار است. حتی پیشرفتهترین شبکههای بینایی کامپیوتری در مواجهه با تصاویر کمکنتراست، زوایای غیرمنتظره یا انواع آرتیفکتها دچار افت عملکرد میشوند. نرمافزار LumineticsCore (پیشترIDx-DR ) که یکی از معدود ابزارهای تایید شده برای عملکرد کاملا خودکار در تشخیص رتینوپاتی دیابتی است با محدودیتهایی همراه است: بیمار باید بزرگسال و بدون سابقه بیماری باشد؛ دو تصویر فوندوس با کیفیت حداقل ۱۰۰۰در۱۰۰۰ پیکسل لازم است و اگر کیفیت تصویر به دلیل تابش نور، مردمک کوچک یا فوکوس ضعیف پایین باشد، سیستم باید فرآیند را متوقف کرده و بیمار را به متخصص ارجاع دهد.حتی اگر شواهد قویتر و عملکرد بهتر بتواند این دو مانع را برطرف کند، باز هم الزامات دیگری موجب تاخیر در استفاده گسترده خواهند شد.
برای مثال اگر مدلی دوباره آموزش داده شود-even only slightly- به تاییدیه جدید نیاز دارد، حتی اگر نسخه قبلی تایید شده باشد. این موضوع باعث میشود بازار از تواناییهای مرزی فناوری عقب بماند. و حتی در صورت تایید مدلهای خودکار، شرکتهای بیمه مسوولیت پزشکی تمایلی به پوشش دادن آنها ندارند. خطاهای تشخیصی پرهزینهترین خطاهای پزشکی در آمریکا هستند و رادیولوژیستها همیشه از متهمان اصلی هستند. بیمهگران معتقدند نرمافزارها احتمال خطاهای فاجعهبار را افزایش میدهند چون یک الگوریتم معیوب میتواند همزمان به افراد زیادی آسیب بزند.
اکنون بسیاری از قراردادها عباراتی مانند «پوشش فقط شامل تفسیرهایی است که توسط پزشک مجاز بازبینی و تایید شده باشد؛ هیچ مسوولیتی برای تشخیصهای خودکار نرمافزار وجود ندارد» را درج میکنند. یکی از بیمهگران حتی بندی با عنوان «محرومیت مطلق در مورد هوش مصنوعی» دارد.
بدون پوشش بیمه مسوولیت، بیمارستانها نمیتوانند اجازه دهند الگوریتمها گزارشها را امضا کنند. در مورد LumineticsCore، شرکت سازنده خودDigital Diagnostics یک بیمه مسوولیت محصول و بند جبران خسارت ارائه میدهد، به شرط آنکه کلینیک دقیقا مطابق برچسب FDA عمل کرده باشد. امروزه اگر بیمارستانهای آمریکایی بخواهند خوانش کاملا خودکار داشته باشند، باید باور کنند که این مدلها به اندازهای صرفهجویی یا افزایش بهرهوری ایجاد میکنند که بتوانند برای تغییر مقررات و سیاستهای بیمهای فشار بیاورند اما فعلا استفاده از آنها بسیار محدود است. یک تحقیق در ۲۰۲۴ نشان داد فقط ۴۸درصد رادیولوژیستها از هوش مصنوعی در کار خود استفاده میکنند. یک نظرسنجی در ۲۰۲۵ گزارش داد تنها ۱۹درصد از کاربران اولیه هوش مصنوعی در رادیولوژی، میزان موفقیت «زیاد» را گزارش کردهاند.
هوش مصنوعی بهتر، MRI بیشتر
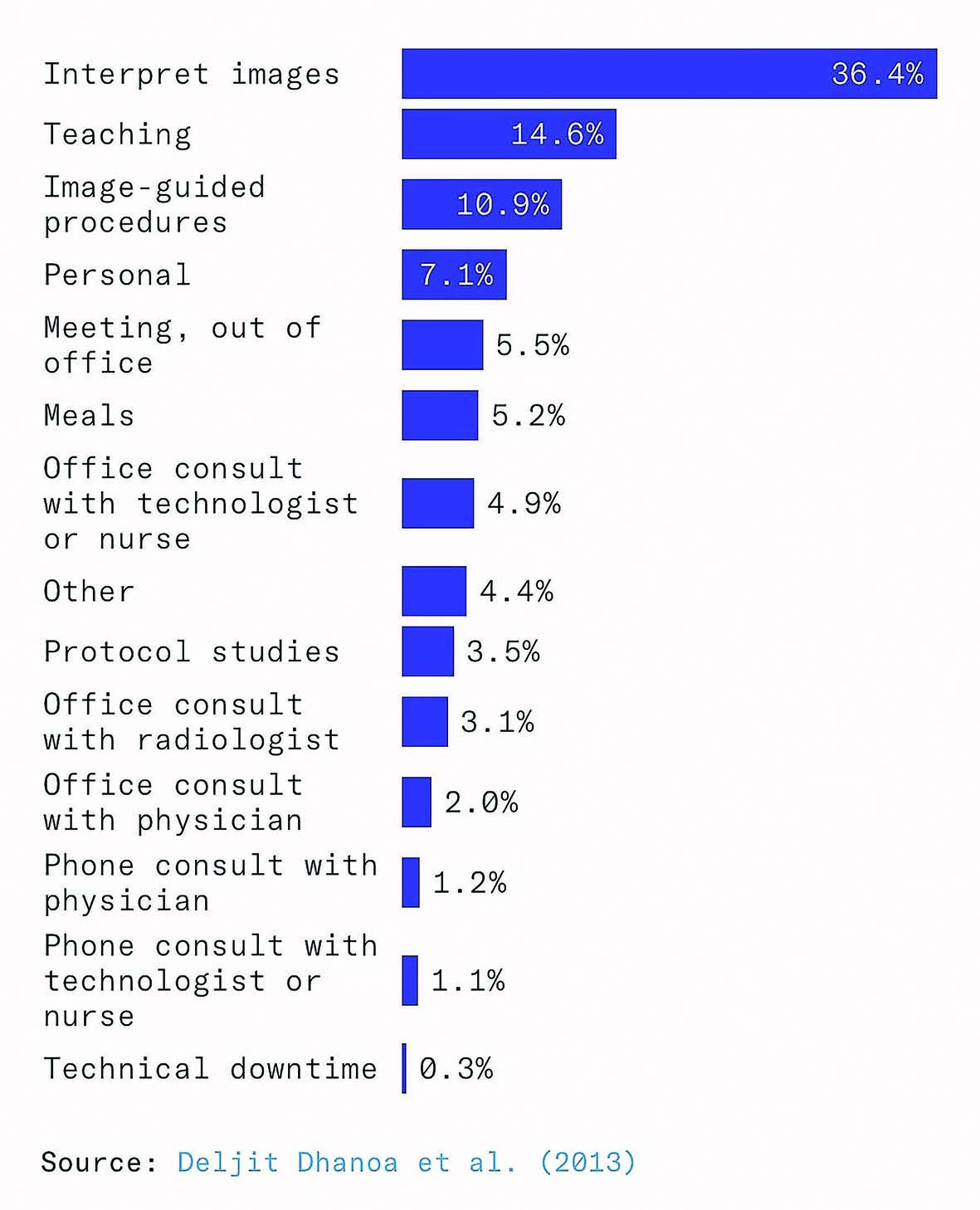
حتی اگر مدلهای هوش مصنوعی آنقدر دقیق شوند که اسکنها را بهتنهایی بخوانند، رادیولوژیستها ممکن است پرمشغلهتر از قبل شوند، نه بیکار. یک مطالعه در ۲۰۱۲ نشان داد که فقط ۳۶درصد از زمان رادیولوژیستها صرف تفسیر مستقیم تصاویر میشود. بخش عمده زمان صرف مواردی چون نظارت بر تصویربرداری، ارتباط با پزشکان و بیماران، آموزش دستیاران رادیولوژی و تکنولوژیستها و بازبینی درخواستها و پروتکلهای تصویربرداری میشود. بنابراین اگر هوش مصنوعی در تفسیر تصاویر بهتر شود، رادیولوژیستها زمان خود را به سمت وظایف دیگر جابهجا میکنند و اثر جایگزینی کاهش مییابد.
وقتی انجام یک کار سریعتر یا ارزانتر میشود، ممکن است حجم انجام آن هم افزایش یابد. این همان «پارادوکس جوونز» است. نمونه تاریخی آن در رادیولوژی وجود دارد: در اوایل دهه۲۰۰۰ بیمارستانها از فیلم به سیستم دیجیتال مهاجرت کردند. بهرهوری رادیولوژیستها افزایش یافت و زمان خواندن کاهش پیدا کرد. در بیمارستان ونکوور، بهرهوری در رادیولوژی ساده ۲۷درصد و در CT حدود ۹۸درصد افزایش یافت. هیچکس اخراج نشد. در عوض، میزان کل تصویربرداری در آمریکا بین سالهای ۲۰۰۰ تا ۲۰۰۸ حدود ۶۰درصد افزایش یافت. دلیل این افزایش، بیشتر شدن تعداد اسکنها در هر ویزیت پزشک بود، نه افزایش تعداد مراجعات. پیش از دیجیتالی شدن، زمان انتظار برای گزارش بسیار بالا بود اما پس از دیجیتالی شدن، این زمانها نصف شد.
با اسکنهای سریعتر، پزشکان گزینههای بیشتری داشتند. CT تمام بدن که روزی فقط در تروماهای شدید استفاده میشد حالا به انتخابی رایج تبدیل شده است. این همان «تقاضای کششپذیر» است: وقتی هزینه (زمان یا پول) کاهش مییابد، تقاضا افزایش مییابد.
دهه نخست انتشار
در دهه گذشته، پیشرفتهای تفسیری هوشمصنوعی بسیار جلوتر از گستردگی استفاده از آن بوده است. صدها مدل میتوانند خونریزی، ندولها، یا لختهها را تشخیص دهند اما استفاده واقعی در عمل بالینی محدود باقی مانده است. برخلاف پیشبینیها، تعداد رادیولوژیستها و حقوق آنها همچنان افزایش یافته است. وعده هوشمصنوعی در رادیولوژی بیش از اندازه براساس نتایج معیارها بزرگنمایی شده است.
مدلهای چند وظیفهای بزرگ ممکن است پوشش را گستردهتر کنند و مجموعه دادههای جامعتر میتوانند شکافها را کاهش دهند اما بسیاری از موانع با مدلهای بهتر هم برطرف نمیشود: نیاز به گفتوگو با بیمار، ریسک مسوولیت پزشکی و الزامات قانونی برای اعتبارسنجی. این موانع باعث میشوند جایگزینی کامل انسان پرهزینه و پرریسک باشد و «انسان + ماشین» ترکیب پیشفرض باقی بماند.در برخی صنایع شرایط متفاوت است: برای مثال پلتفرمهای بزرگ اینترنتی تا ۹۸درصد تصمیمات نظارت محتوا را با ماشین انجام میدهند اما بسیاری از مشاغل پیچیده شبیه رادیولوژی هستند: کارها متنوع هستند، ریسک بالا است و تقاضا کششپذیر.
وقتی چنین شرایطی برقرار باشد، باید انتظار داشته باشیم که نرمافزار در ابتدا باعث افزایش کار انسانی شود، نه کاهش آن.
درس ۱۰ساله رادیولوژی این است: نه خوشبینی افراطی نسبت به بهرهوری، نه ترس از جایگزینی. مدلها میتوانند بهرهوری را افزایش دهند اما پیادهسازی آنها به رفتار، نهادها و انگیزهها بستگی دارد. دستکم فعلا، این پارادوکس برقرار است: هر چه ماشینها بهتر میشوند، رادیولوژیستها مشغولتر میشوند.